An Introduction to PPO
An Introduction to PPO
Introduction:
PPO stands for Proximal Policy Optimization. Its a Policy gradient method for Reinforcement Learning(RL). It has much better performance than the TRPO (Trust Region Policy Optimization) but very simpler to Implement, more general and have better sample complexity.
PPO Paper: https://arxiv.org/pdf/1707.06347.pdf
Firstly, we see the basic RL setup , then explain Policy Gradients and then show the application of Importance sampling and finally the need for Policy Bounding. Basic math equations are covered as it cant be avoided altogether to understand Policy gradient and PPO .
Reinforcemet Learning Setup:
A standard RL setup consists of
- Agent
- Environment
The Agent Interacts with the Environment by taking an action and collects the rewards and observes the next state of the environment. The environment is assumed to be fully observable so that we can formulate this as Markov Decision Process.(MDP)
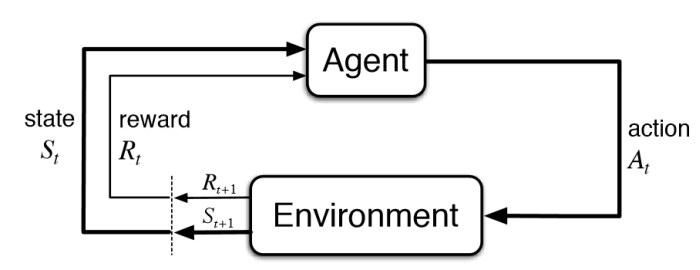
# This can be shown as ,
observation, reward,_ = env.step(action)
The Agent interacts with the environment in discrete timesteps ‘t’. For each time step, the agent receives an observation , selects an action ,following the policy(probability of chossing action ‘a’ given state ‘s’) . The Agent receives a scalar reward and transitions to the next state
Policy is the mapping of the probability of different actions for a state
The Returns from a state is defined as the sum of discounted future Rewards
Here is the discount factor The Objective of Reinforcement Learning is to Maximize Returns. That’s it !
Policy Gradients:
The Policy Gradient Methods try to model a Policy that will maximize the expected Rewards. The Policy is usually learnt by a function approximator- where is the parametrized network.
The Objective is :
Maximize the Expected rewards computed from a trajectory , generated by the policy .
To find the best for any function we need to do stochastic gradient ascent on
Here is our sum of rewards objective in our previous equation. so we need to find
How to Calculate
Using Log Derivative Trick
Mathematical expectation, also known as the expected value, is the summation or integration of a possible values from a random variable. It is also known as the product of the probability of an event occurring, and the value corresponding with the actual observed occurrence of the event
So the expected value is the sum of: [(each of the possible outcomes) × (the probability of the outcome occurring)].
The Expectation of under the distribution
Expanding for
Multiply and divide by p(x)
Using the log formulae
Again rewriting using Expectation:
We will replace the x with the trajectory .Next step is to find the log probability of the trajectory .
Computation of
Let,
- starting state distribution
- Policy - probability of taking an action given a state
P - Dynamics of Environment
Trajectory = Initial State + Further Transitions from the initial state based on actions taken following policy .
We can notice that when taking the gradients , the dynamics disappear and thus , Policy gradients doesn’t need to know the environment Dynamics.
Objective:
Substituting (3) in (2) and then (2) in (1)
- The reward function that we want to maximize.
The Expectation of the rewards over the trajectory following the policy
This is the Objective in Policy Gradient problem
As expained in Pong From Pixels
This equation is telling us how we should shift the distribution (through its parameters ) if we wanted its samples to achieve higher scores, as judged by the Reward Function. It’s telling us that we should take this direction given by gradient of (which is a vector that gives the direction in the parameter space ) and multiply onto it the scalar-valued score Rewards. This will make it so that samples that have a higher score will “tug” on the probability density stronger than the samples that have lower score, so if we were to do an update based on several samples from p the probability density would shift around in the direction of higher scores, making highly-scoring samples more likely.
We see that the Rewards (scalar values) is multiplied with the Gradient of the Log probability of the action , given state. The Gradient Vector point the direction we should move to optimize the objective. The Gradient is factored by the Rewards.
This enables Probability density function moves towards the action probabilities that creates high score.
Good Stuff is made More Likely.
Bad stuff is made less likely .
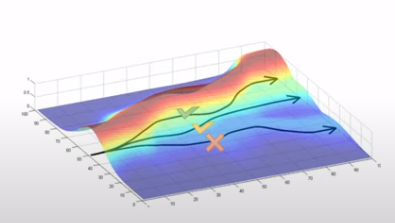
CS285: Trajectories with Good and Bad Rewards
As explained in GAE paper, these are some of the variations of this Policy Gradient where the Rewards function is replaced with other expressions for bias Variance Trade-off

GAE Paper : https://arxiv.org/pdf/1506.02438.pdf
Importance Sampling in Policy Gradients
Policy Gradient is On-Policy - Every time we generate a policy we need to generate own samples
So the steps are
- Create Sample with the current Policy.
- Find the Gradient of the objective.
- Take a gradient step for Optimization.
This is because, The objective is the Expectation of the grad log over the current Trajectory generated by the current Policy .
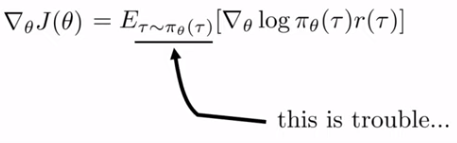
CS285:https://youtu.be/Ds1trXd6pos?t=3415
Once we take the gradient over the policy , the policy is changed and we cannot use the Trajectory generated previously. We need to new samples again with the current policy.
This is shown below
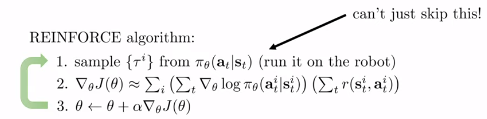 CS285:https://youtu.be/Ds1trXd6pos?t=3415
CS285:https://youtu.be/Ds1trXd6pos?t=3415
What if we don’t have the samples from the policy instead we have
Importance Sampling comes into play here!
Importance Sampling:
From Wikepdia,
In statistics, importance sampling is a general technique for estimating properties of a particular distribution, while only having samples generated from a different distribution than the distribution of interest.
Expectation of random variable under distribution in terms of distribution under
The Expectation of a random variable under distribution
Multiplying and dividing by
Rearranging
This is equal to the Expectation under distribution given by
So Expectation under for is equal to the Expectation under with the ratio times
Plugging this for the old policy distribution , The objective becomes
Quick Recap:
The original Objective
Estimating for the new parameters ’ with Importance Sampling
Using identity ,
Importance sampling enables us to use the samples from the old policy to calculate the Policy Gradient
Problems with Importance Sampling:
Expanding
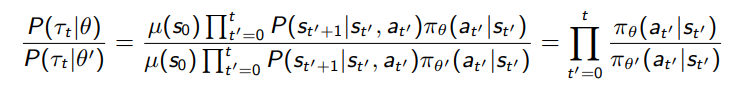
http://rail.eecs.berkeley.edu/deeprlcourse-fa17/f17docs/lecture_13_advanced_pg.pdf
The Policy Gradient Objective with IS and Advantage Function is
High Variance in Importance Sampling :
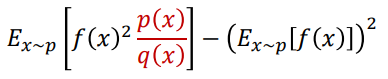
The variance of the Importance Sampling Estimator depends on the ratio .
As see in above equation for the ratio , the probabilities are all multiplied and many small differences multiply to become a larger.
This ratio if its large ,may cause the gradients to explode .
This also means , we may need more sample data if the ratio is far from 1.
Unstable Step Updates:
The trajectories generated with the old policy , they may be having the states, that are not that interesting. May be they all have lesser rewards then that of the current Policy.But the new policy is dependent on the old policy
We need to use the old policy and make confident updates when we take a gradient step
step updates options
- Too large step means, performance Collapse
- Too small ,progress very slow.
- The right step changes depends where we are in the policy space
Adaptive learning rate - like Adam - doesn’t work well
So the interesting thing is here that the policies nearer in parameter space differs so much in the policy space.
This is because distance in Policy space and Parameter space are different.

http://rail.eecs.berkeley.edu/deeprlcourse-fa17/f17docs/lecture_13_advanced_pg.pdf
We need to find a policy update, that reflects the underlying structure of the policy space as a function of the parameter space.
Policy Bounds
Somehow we should bound this difference between these distributions (ie) the Old policy distribution and new policy distribution .
We want an update step that is:
- uses rollouts collected from the most recent policy as efficiently as possible
- and takes steps that respect distance in policy space as opposed to distance in parameter space
Relative Policy Performance Bounds:
For this ,we check the performance of one policy to the performance of another policy and check that they are in specific bounds
As explained in this Lecture
We want to produce a new policy update method, which is going to take the form of some kind of optimization problem as in local policy search which is a super class of policy gradient algorithm. We want to maximize some objective, subject to the constraint .. that we are going to say close to the previous policy. So we are going to figure out what that objective is going to be.
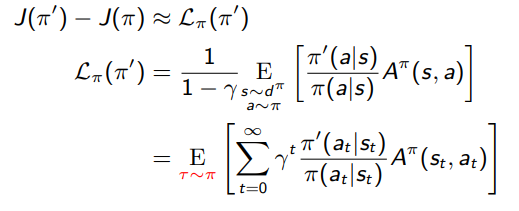
is our new objective. We call this a surrogate objective.
Now,We can use trajectories sampled from the old policy along with the Advantage calculated from the old policy Trajectory. Still we need the new policy action probability , however we don’t want to rollout for the new policy to collect the rewards.
So what about the constraint/Bounds?
As seen from the above equation, is the Surrogate Objective. We maximize that surrogate objective , so as to reduce absolute value in the Left hand of the below equation. We do it such a way to keep the KL divergence in some limits.
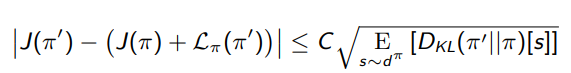
The policies should be bound by KL divergence. If KL divergence of two policies are less, they are close in Policy space
Kullback-Leibler Divergence:
Its a measure of difference between two distributions. The distance between two distributions P(x) and Q(x) given as
Its the expectation of the Logarithmic difference between the two probabilities P and Q.
KL Divergence of Two policies can be written as
TRPO sneak peak:
The objective is
So,we Maximize the objective , subjecting to condition, the KL Divergence between two policies are less than a value $\delta$. This can be written as
With Lagrangian Dual Trick, we write as unconstrained optimization problem
Here penalty coefficient is constant value,Natural Policy Gradient is used , and additionally the computational Intensive Hessian Matrix has to be calculated.

http://rail.eecs.berkeley.edu/deeprlcourse-fa17/f17docs/lecture_13_advanced_pg.pdf
More details on TRPO in this medium post by Jonathan Hui
Proximal Policy Optimization:
In PPO we try to constraint the new policy near to the old policy but ,without computing Natural Gradient. There are two variants.
- Adaptive KL Penalty
This solves a constraint problem similar to TRPO. PPO uses a soft penalty coefficient to penalize the KL divergence and its adjusted appropriately over the course of the training. This is a first order method
The Objective is :
TRPO(Primal Dual descence strategy) alternates between update the policy parameters and Lagrange multipliers in the same optimization update iteration .However In PPO we keep the penalty coefficient constant for the whole section of optimization and then afterwards modify it.Compute,
If . The KL divergence is larger than the target value . Increase the Penalty Coefficient
If . The KL divergence is too small than the target, probably lower the penalty coefficient.

CS294: http://rail.eecs.berkeley.edu/deeprlcourse-fa17/f17docs/lecture_13_advanced_pg.pdf
- Clipped Objective
This is much simpler than PPO with KL Penalty.
As usual , the objective function is :
We define as the likelihood ratio
We just want to clip this ratio.
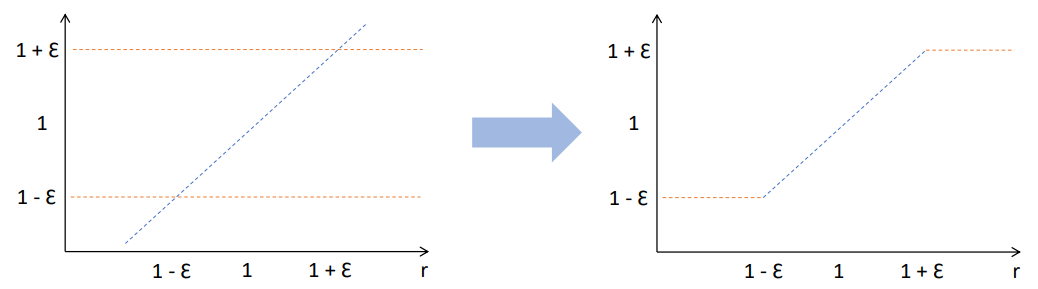
https://cs.uwaterloo.ca/~ppoupart/teaching/cs885-spring18/slides/cs885-lecture15b.pdf
We can see that the ratio r is clipped between and where is the clipping hyperparameter
The Clipped objective is :
We take the minimum between the unclipped value and the clipped value . This make the policy update to be more pessimistic and discourages from make abrupt changes in policy updates based on bigger/smaller rewards.
We don’t have any constraints, no Penalties .There is no KL divergence here , its much simpler and the clipping is easier to implement.

We should note the partial trajectories and the minibatches update for a batch.
PPO practice:
When we use PPO network in an architecture like Actor Critic , (where Policy is actor and Value is critic ) , we use the following in the objective
-
Clipped rewards(Surrogate Function)
-
Squared Error Loss (Critic)
-
Entropy (To encourage exploration)

https://cs.uwaterloo.ca/~ppoupart/teaching/cs885-spring18/slides/cs885-lecture15b.pdf
PPO Implementation:
There are many github repositories that has PPO implementation. There is one from openai/baselines ,famous pytorch implementation by ikostrikov , QunitinFettes, CleanRL , higgsfield/RL-Adventure etc..
There is a nice blog post on PPO Implementation details .Please check this list for your implementation details.
I have implemented a PPO Notebook for continuous environment with the boiler plate code provided by Yandex. My implementation may not be perfect.
I will just highlight few items here.
Network Architecture:
Its suggested to use Orthogonal initialisation with parameter and biases zero.
def layer_init(layer, std=np.sqrt(2), bias_const=0.0):
'''
https://github.com/vwxyzjn/cleanrl/blob/
418bfc01fe69712c5b617d49d810a1df7f4f0c14/cleanrl/ppo_continuous_action.py#L221
'''
nn.init.orthogonal_(layer.weight, std)
nn.init.constant_(layer.bias, bias_const)
return layer
The network is kind of Actor critic,wherein we use one network for policy and another one for values. The activation function is tanh.
class Model(nn.Module):
def __init__(self,num_inputs,num_outputs):
super(Model,self).__init__()
self.fc1 = layer_init(nn.Linear(input_shape,64))
self.fc2 = layer_init(nn.Linear(64,64))
self.fc_Policy = layer_init(nn.Linear(64,n_actions))
self.fc_Value = layer_init(nn.Linear(64,1))
self.covariance = nn.Parameter(torch.zeros(1,n_actions))
def Policy_network(self,x):
'''
The network predicts the mean and covariance(log of standard deviation)
'''
x = torch.tanh(self.fc1(x))
x = torch.tanh(self.fc2(x))
mean = self.fc_Policy(x)
logstd = self.covariance.expand_as(mean)
return mean,logstd
def Value_network(self,x):
'''
The network predicts the Value Function
'''
x = torch.tanh(self.fc1(x))
x = torch.tanh(self.fc2(x))
x = self.fc_Value(x)
return x
This Model is wrapped with another Class Policy to call in the Model in two different conditions
-
When in Collecting partial Trajectories
This is called partial trajectories as we wont collect the trajectory until the end. But we just collect a fixed set of tuples {actions, log_probabilities,values} for the policy
if not training:
'''
training=False -- Value
Input is Observation
Sample action for a Trajectory
return {"actions:","log_probs","values"}
'''
with torch.no_grad():
x = torch.Tensor(inputs).unsqueeze(0)
mean,logstd = self.model.Policy_network(x)
std = torch.exp(logstd)
distrib = Normal(mean,std)
action = distrib.sample()[0]
log_prob = distrib.log_prob(action).sum(1).view(-1).cpu().detach().numpy()
value = self.model.Value_network(x).view(-1).cpu().detach().numpy()
return {"actions":action.detach().numpy(),"log_probs":log_prob,"values":value}
-
When in training
Just return the action distribution along with the values. This will be called when making every step update.
else:
'''
training=True - - Policy & Value
Input is Observations
return {"distribution","values"}
'''
x = torch.Tensor(inputs)
mean,logstd = self.model.Policy_network(x)
std = torch.exp(logstd)
distrib = Normal(mean,std)
value = self.model.Value_network(x)
return {"distribution":distrib,"values":value}
Generalized Advantage Estimate GAE:
We use an Advantage Estimator that has two parameters for bias-variance trade off as explained in GAE paper
We initialize all the values first .
We have the last observed state in the Trajectory . To get the values for that last state, we call the Network model
advantages = []
returns =[]
lastgae = 0
rewards = trajectory["rewards"]
values = trajectory["values"]
dones = 1- trajectory["resets"]
#Get the latest state
last_state = trajectory["state"]["latest_observation"]
# Output of the network for the 'next_state' input
network_output =self.policy.act(last_state, training=False)
last_value = network_output["values"]
values = np.append(values,[last_value])# Append the next value
Next , we loop through to calculate the Advantage. We calculate the returns as advantage+values
# https://github.com/colinskow/move37/
# blob/f57afca9d15ce0233b27b2b0d6508b99b46d4c7f/ppo/ppo_train.py#L69
for step in reversed(range(len(rewards))):
td_delta = rewards[step] + self.gamma * values[step+1] * dones[step] - values[step]
advantage =lastgae= td_delta + self.gamma*self.lambda_*dones[step]*lastgae
advantages.insert(0,advantage)
returns.insert(0,advantage+values[step])
Losses
Policy Loss
The clipped objective is
Advantage is calculated from old policy. Ratio is calculated between new policy and old policy.
def policy_loss(self, trajectory, act):
""" Computes and returns policy loss on a given trajectory. """
actions = torch.tensor(trajectory["actions"]).to(device)
old_log_probs = torch.tensor(trajectory["log_probs"]).to(device).flatten()
new_distrib = act["distribution"]
new_logprobs = new_distrib.log_prob(actions).sum(1)
entropy = new_distrib.entropy().sum(1)
self.entropy_loss = entropy.mean()
ratio = torch.exp(new_logprobs - old_log_probs)
surrogate1 = ratio * -torch.Tensor(trajectory["advantages"]).to(device)
surrogate2 = torch.clamp(ratio,1-self.cliprange,1+self.cliprange)*-torch.Tensor(trajectory["advantages"])
policy_loss = torch.mean(torch.max(surrogate1,surrogate2))
return policy_loss
Value Loss:
We use clipped value loss function.
def value_loss(self, trajectory, act):
""" Computes and returns value loss on a given trajectory. """
new_values = act["values"].flatten()
# returns(Target Values)= Advantage+value
returns = torch.tensor(trajectory["value_targets"]).to(device) #Advantage+value
old_values = torch.tensor(trajectory["values"]).to(device).flatten() # Old Values
# Squared Error Loss
v_loss1 =(returns - new_values ).pow(2) # Target_values - New_values
clipped_values = old_values+ torch.clamp(new_values - old_values,-self.cliprange,self.cliprange)
v_loss2 = (clipped_values - returns ).pow(2) # Target_values - clipped_values
value_loss = 0.5*(torch.max(v_loss1,v_loss2)).mean()
return value_loss
Total Loss:
total_loss = policy_loss + self.value_loss_coef * value_loss - self.entropy_coef*self.entropy_loss
Helpful Blogs:
-
https://lilianweng.github.io/lil-log/2018/04/08/policy-gradient-algorithms.html
-
https://cs.uwaterloo.ca/~ppoupart/teaching/cs885-spring18/slides/cs885-lecture15b.pdf
-
http://rail.eecs.berkeley.edu/deeprlcourse-fa17/f17docs/lecture_13_advanced_pg.pdf
- Expectation
- Pong from Pixels
Video Tutorials:
- CS 285 - Berkley Deep RL Lectures especially this on TRPO and PPO
- PPO from CS 885 Waterloo Deep RL course .
- Coding Tutorial from schoolofai